
研究背景
二硫化鉬(MoS2)是由天然鉬精礦粉經化學提純後改變分子結構而製成的固體粉劑,被譽為“高級固體潤滑油王”。 MoS2是由三層原子層構成,鉬原子層夾在兩層硫原子層之間,形成類似“三明治”結構的特殊層狀形貌,因此具有非常優良的各向異性、催化性能以及較低的摩擦係數[1]。隨著研究的不斷深入,尤其是近些年很多國內外研究學者對二維MoS2的深入研究,越來越多的性能被逐漸發現。由於具有獨特的結構和性能,MoS2在光催化、電催化、儲氫媒介、太陽能電池及鋰離子電池、場效應電晶體、發光二極體、柔性器件、潤滑劑、吸附劑及MoS2層間化合物等方面應用十分廣泛[2]。因此對MoS2的分子結構研究也越來越熱。拉曼光譜可收集入射光子和樣品間相互作用產生了與入射光子不同波長的散射光子,並研究其波長分佈特點,實現化學品分析、分子結構表徵、成鍵效果、樣品所處環境以及內部應力分佈等研究目標,是一種強大的表徵工具,也是當前表徵材料結構特徵最有效手段之一。
測試樣品及實驗儀器搭建
本次檢測使用如海的可擕式深製冷532拉曼光譜儀,搭配一維可微調檢測支架對樣品進行檢測。

2. 儀器搭建

實驗結果
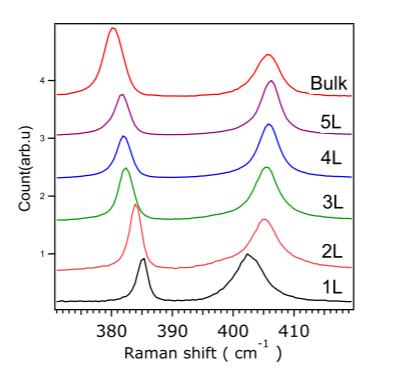
測試結果見圖1,圖中可觀察到多個二硫化鉬拉曼特徵峰,根據文獻資料顯示,其中380、410cm-1兩處特徵峰可以反映的二硫化鉬層數,隨著二硫化鉬層數的增多,383cm-1處指紋峰向低波數方向移動,408cm-1處指紋峰向高波數移動(如圖2)[3]。圖1中二硫化鉬拉曼特徵峰位於377和415cm-1,表明該樣品可能為多層二硫化鉬堆疊而成。
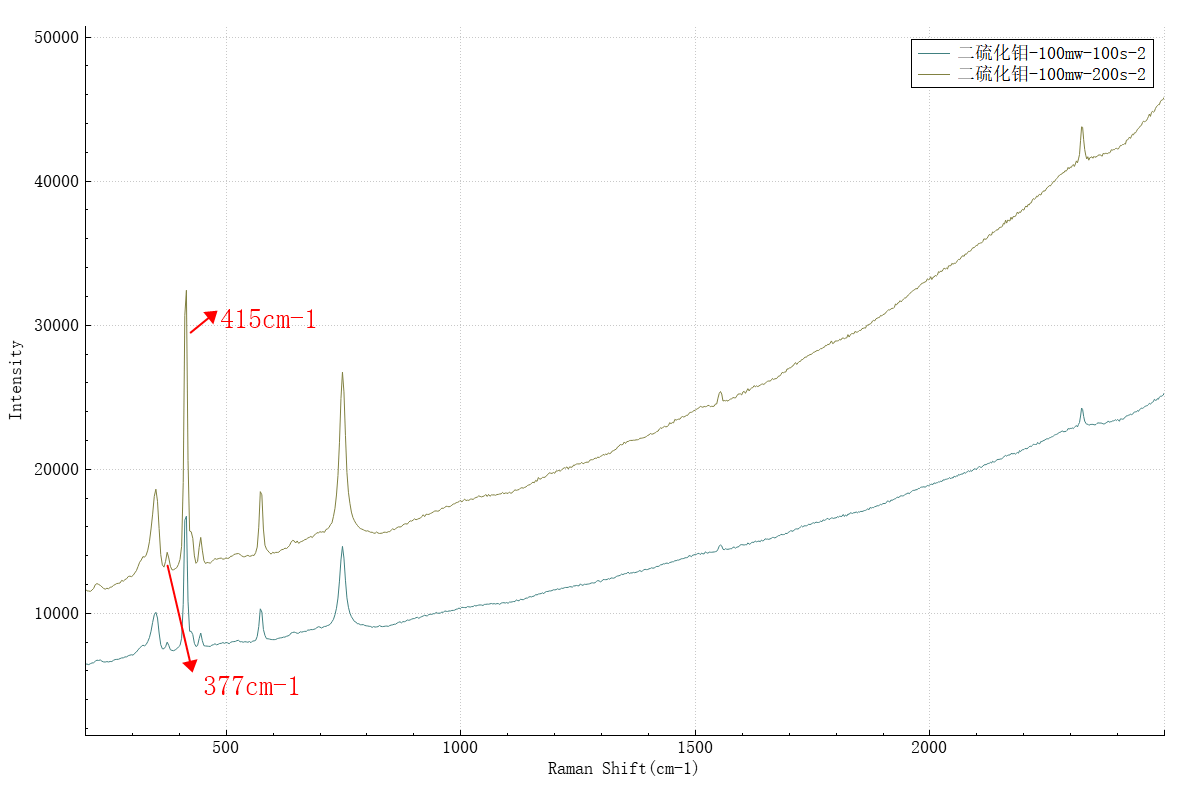
圖1 二硫化鉬拉曼測試結果
實驗結論
使用如海的可擕式深度制冷532拉曼光譜儀可以檢測到二硫化鉬拉曼訊號,該研究對後續表徵二硫化鉬材料結構有著重要意義。
參考文獻
[1] 賈園, 魏萌, 高樂樂, 等. 二硫化鉬的表面改性及其應用研究進展.化學工程師, 2019, 33(3): 53.
[2] 李晶,王宇晴,劉東新,等.二硫化鉬性能及應用研究進展[J].粉末冶金技術, 2021(005):039.
[3] Mohamed, Boukhicha, Matteo, et al. Anharmonic phonons in few-layer MoS2: Raman spectroscopy of ultralow energy compression and shear modes[J]. Physical Review B, 2013.
產品推薦
Portman-532可擕式拉曼光譜儀產品簡介
Portman-532可擕式拉曼光譜儀配置了一款適用於拉曼光譜檢測的面陣式光纖光譜儀,相比傳統的532nm拉曼光譜儀,Portman-532的靈敏度得到很大的提升,能夠檢測到細胞級別的微弱拉曼訊號。適用於對原材料的篩選、現場檢測、石墨烯合成反應、生物醫療、體外診斷及物質分析鑑定等場景;使用方便,操作簡單。檢測結果客觀準確。客戶可根據應用需求選擇最適合的產品。
產品特點
- 檢測範圍廣:200-4000cm-1
- 訊號靈敏度高,可分辨矽片的二階峰
- 能測出雞肉脂肪細胞訊號
- 高度整合,輕巧便捷
- 高穩定性